












Customized video generation aims to produce videos featuring specific subjects under flexible user-defined conditions, yet existing methods often struggle with identity consistency and limited input modalities. In this paper, we propose HunyuanCustom, a multi-modal customized video generation framework that emphasizes subject consistency while supporting image, audio, video, and text conditions. Built upon HunyuanVideo, our model first addresses the image-text conditioned generation task by introducing a text-image fusion module based on LLaVA for enhanced multi-modal understanding, along with an image ID enhancement module that leverages temporal concatenation to reinforce identity features across frames. To enable audio- and video-conditioned generation, we further propose modality-specific condition injection mechanisms: an AudioNet module that achieves hierarchical alignment via spatial cross-attention, and a video-driven injection module that integrates latent-compressed conditional video through a patchify-based feature-alignment network. Extensive experiments on single- and multi-subject scenarios demonstrate that HunyuanCustom significantly outperforms state-of-the-art open- and closed-source methods in terms of ID consistency, realism, and text-video alignment. Moreover, we validate its robustness across downstream tasks, including audio and video-driven customized video generation. Our results highlight the effectiveness of multi-modal conditioning and identity-preserving strategies in advancing controllable video generation.
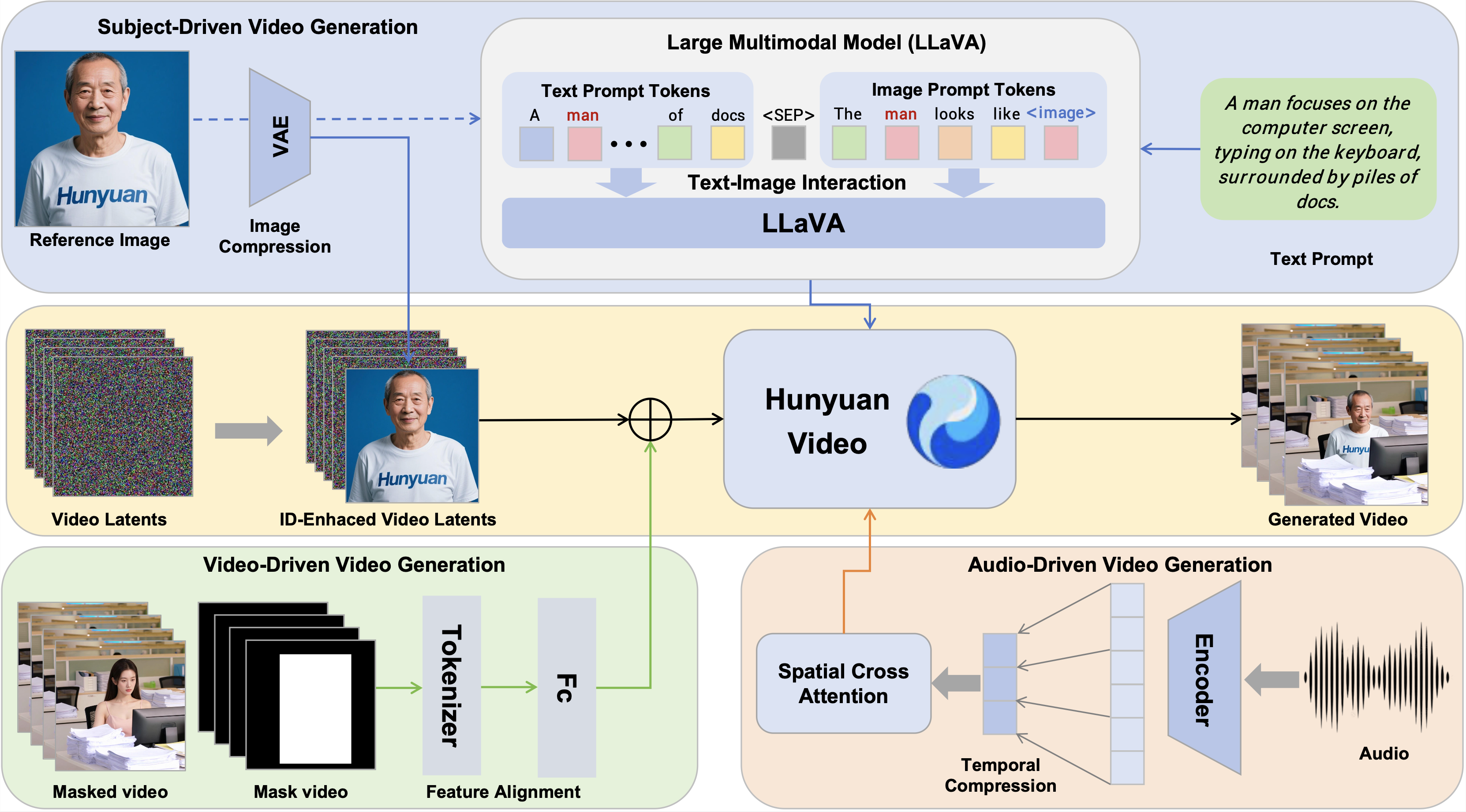
We propose HunyuanCustom, a multi-modal, conditional, and controllable generation model centered on subject consistency, built upon the Hunyuan Video generation framework. It enables the generation of subject-consistent videos conditioned on text, images, audio, and video inputs. Specifically, HunyuanCustom introduces an image-text fusion module based on LLaVA to facilitate interaction between images and text, allowing identity information from images to be effectively integrated into textual descriptions. Additionally, an image ID enhancement module is proposed, which concatenates image information along the temporal axis and leverages the video model's efficient temporal modeling ability to enhance subject identity throughout the video. To support conditional injection of audio and video, HunyuanCustom designs distinct injection mechanisms for each modality, which are effectively disentangled with the identity condition module. HunyuanCustom ultimately achieves decoupled control over image, audio, and video conditions, demonstrating great potential in subject-centric multi-modal video generation.
Prompt: A man is listening to music and cooking snail noodles in the kitchen.
Prompt: In a music rehearsal room, a woman holds a violin, concentrating on playing; the melodious sound reverberates within.
Prompt: A girl plays "house" with plush toys in the living room.
Prompt: A dog is chasing a cat in the park.
Prompt: Family members sit around and share the dumplings on the porcelain plate with dipping sauce, full of reunion happiness.
Prompt: In an outdoor cafe, a woman wearing a dress is enjoying a delicious dessert. She sits in a comfortable chair with a cup of coffee in her hand, her face full of happiness.
Prompt: A woman is holding a paintbrush, drawing a picture of a cat on her home blackboard.
Prompt: A woman rides a tiger, wandering through the fields.
Prompt: A woman is boxing with a panda, and they are at a stalemate.
Prompt: A man is presenting the chips in his hand beside the swimming pool.
Prompt: A man is drinking Moutai in the pavilion.
Prompt: A man is sitting in a spacious and bright living room, smiling and greeting a cute penguin. The penguin nods back at him in a friendly manner, as if responding to his greeting.
Prompt: A woman wearing Hanfu is reading a book in the study room.
Prompt: A man wearing Hanfu walks across an ancient stone bridge holding an umbrella, raindrops tapping against it.
Reference Image

Source Video
Edit Result
Reference Image

Source Video
Edit Result
Reference Image

Source Video
Edit Result
Reference Image

Source Video
Edit Result
Reference Image

Source Video
Edit Result
Reference Image

Source Video
Edit Result
Reference Image

Source Video
Edit Result
@misc{hu2025hunyuancustommultimodaldrivenarchitecturecustomized,
title={HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation},
author={Teng Hu and Zhentao Yu and Zhengguang Zhou and Sen Liang and Yuan Zhou and Qin Lin and Qinglin Lu},
year={2025},
eprint={2505.04512},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.04512},
}
